Bienvenidos una vez mas a este espacio, en esta ocasión estaremos creando un Bot de telegram al cual le estaremos integrando chatgpt.
Este será un sencillo ejemplo de cómo integrar el api de OpenAI con el api de Telegram
Como primer paso debemos crear un api key de OpenAI para poder interactuar con la misma, para hacer esto nos dirigimos a https://platform.openai.com/account/api-keys y creamos nuestra key presionando el botón
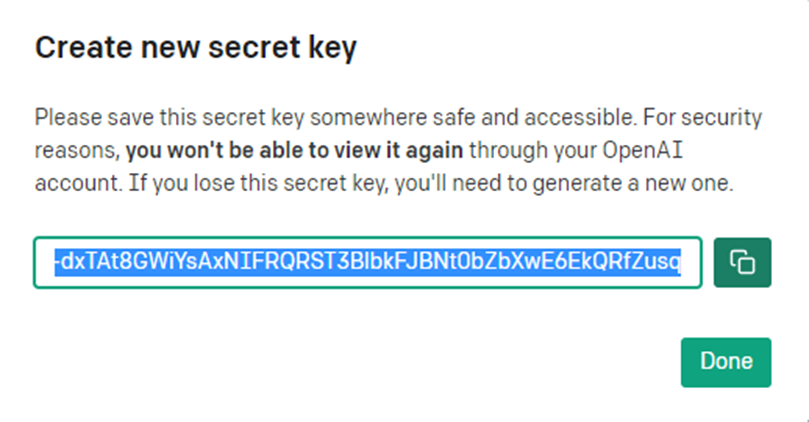
Le asignamos un nombre y presionamos créate secret key
Una vez presionado el botón OpenAI nos advierte que debemos guardar la key en un lugar seguro y por razones de seguridad no seremos capaces de ver la key nuevamente así que debemos copiar la key y guardarla tal como nos recomienda OpenAI
Una vez creada nuestra key de OpenAI nos dirigimos a Bot Father y creamos nuestro Bot siguiendo las instrucciones y guardamos el token de nuestro Bot
Una vez hecho esto ya estamos listos para empezar con nuestro Bot
Lo primero que debemos hacer es importar los módulos necesarios para nuestro código
el modulo json lo utilizamos para leer el contenido del archivo de configuración, el modulo aiogram es utilizado para interactuar con el api de Telegram y el modulo openai es utilizado para interactuar con el api de OpenAI
yo he creado un archivo de configuración json en el cual almaceno la key de OpenAI y el token de nuestro Bot, esto puede hacerse de esta forma o también puede hacerse almacenando las keys en variables de entorno
Lo siguiente que debemos hacer es leer nuestras keys del archivo de configuración json esto lo hacemos abriendo nuestro archivo con open y json.load() y almacenamos nuestras keys en las variables telegram_token y opeanai_key
# leemos las keys
with open("config.json") as cfg:
data=json.load(cfg)
telegram_token=data["telegram_token"]
openai_key=data["openai_key"]
lo siguiente que hacemos es asignar nuestra key de OpenAI y creamos la instancia del Bot
# Asignamos la key OpenAi
openai.api_key= openai_key
# Creamos La instancia del bot
bot=Bot(token=telegram_token)
Lo siguiente es instanciar nuestro dispatcher el cual es un componente de la biblioteca aiogram que es utilizado para manejar y enrutar mensajes entrantes en un Bot de Telegram. este recibe los mensajes y los dirige a las funciones de manejo adecuadas para su procesamiento.
El dispatcher se encarga de registrar y administrar los controladores de mensajes para diferentes tipos de eventos, tales como mensajes de texto, comandos, actualizaciones de chat entre otros. Puede asociar funciones especificas a estos eventos y ejecutarlas cuando se produzcan
Algunas funciones importantes del Dispatcher incluyen:
register_message_handler(): Permite registrar una función para manejar mensajes de texto entrantes. Se puede especificar opcionalmente una condición para filtrar los mensajes basados en su contenido o atributos.
register_callback_query_handler(): Permite registrar una función para manejar consultas de botones en línea. Estas consultas se generan cuando un usuario interactúa con un botón en línea adjunto a un mensaje.
register_inline_handler(): Permite registrar una función para manejar consultas en línea. Estas consultas se generan cuando un usuario escribe el nombre del Bot seguido de un comando o consulta especial en el campo de entrada de un chat.
register_errors_handler(): Permite registrar una función para manejar errores que ocurren durante la ejecución del Bot. Esto puede ser útil para manejar excepciones y tomar medidas adecuadas en caso de errores.
En este caso nosotros estaremos usando el decorador message_handler para asociar funciones a mensajes.
@disp.message_handler(commands=["start", "help"])
async def bienvenido(message: types.Message):
await message.reply("bienvenido a este bot, preguntame lo que quieras!")
lo que hemos hecho en el código de arriba es crear una función decorada llamada bienvenido la cual se ejecutará cuando se reciba un mensaje que contenga alguno de los comandos especificados en la lista (start o help), esta responderá con el mensaje “bienvenido a este Bot, preguntame lo que quieras!»
Luego creamos otra función la cual manejara cualquier otro mensaje que no sea un comando
esta función utiliza el api de OpenAI para generar una respuesta al mensaje recibido utilizando el modelo text-davinci-003 la respuesta generada se envía como respuesta al mensaje enviado
por último, iniciamos nuestro dispatcher con executor.start_polling(disp)
if __name__ == "__main__":
executor.start_polling(disp)
al ejecutar nuestro código e interactuar con nuestro Bot de telegram
Vemos que nuestro Bot interactúa con nosotros correctamente
Conclusión
En esta ocasión hemos aprendido como crear nuestros bots de telegram y como interactuar con ellos utilizando el api de OpenAI, también hemos visto como utilizar aiogram para crear nuestros bots de una forma más fácil
Sean todos bienvenidos una vez más a este espacio, en esta ocasión estaremos explorando LangChain y estaremos viendo algunos conceptos y un ejemplo practico de su uso
¿Qué es LangChain?
LangChain es un open source framework para construir aplicaciones con LLM (Large languge models), esta permite enlazar LLM con otras fuentes de datos y permite al Modelo interactuar con su entorno
Ventajas de usar LangChain
LangChain ofrece varios componentes tales como, prompt template, models, chains, indexes, agents, que permiten generar aplicaciones mas complejas con LLM de una manera más fácil a continuación conoceremos algunos de estos componentes.
Models
Los modelos nos permiten conectar con Modelos como por ejemplo GPT4. hay dos tipos de modelos los cuales son Language models (Modelos de lenguaje) y Text Embedding Models
Language models (Modelos de lenguaje)
Los modelos de lenguaje nos permiten interactuar con modelos de lenguaje, así como su nombre indica, estos están subdivididos en dos subtipos LLM los cuales toman texto y retornan texto y ChatModels los cuales toman mensajes de chat y retornan mensajes de chat
Text Embedding Models
Esta clase de modelos toma texto como entrada y retorna un Embedding, la cual es una representación numérica de dicho texto
Prompts
Prompt se refiere al texto o a la entrada de nuestro modelo LangChain esta entrada puede ser construida por varios componentes LangChain ofrece PromptTemplate que son los responsables de construir las prompt estos permiten entre otras cosas crear prompts con determinado formato
from langchain.prompts import PromptTemplate, ChatPromptTemplate
string_prompt = PromptTemplate.from_template("tell me a joke about {subject}")
chat_prompt = ChatPromptTemplate.from_template("tell me a joke about {subject}")
string_prompt_value = string_prompt.format_prompt(subject="soccer")
chat_prompt_value = chat_prompt.format_prompt(subject="soccer")
Indexes
El uso más común que se le da a los indexes es extraer información relevante para los LLM los principales indexes están centrados alrededor de vector databases. LangChain cuenta con funcionalidades tales como Document loaders que permiten la carga de documentos, Text splitters que permiten dividir estos documentos en trozos más pequeños, vector stores el cual almacena documentos y sus embeddings asociados y retrievers que obtienen información relevante la cual puede ser combinada con LLM
Chains
Las cadenas nos permiten combinar múltiples componentes para crear aplicaciones. Tenemos cadenas que nos permiten por ejemplo responder preguntas, hacer resúmenes entre otras además podemos crear nuestras propias cadenas
Agents
Los agentes permiten a los LLM interactuar con su entorno por ejemplo podemos crear un agente que le permita al modelo realizar búsquedas por internet
Ejemplo de uso LangChain
A continuación, vamos a hacer un ejemplo de cómo podemos utilizar LangChain de manera práctica, lo que estaremos haciendo es tomar un documento PDF el cual va a ser la fuente de conocimientos externa, y procederemos a hacer preguntas a la IA y le estaremos pasando el documento como contexto
explicación de nuestro Código
El primer paso es importar todas las librerías necesarias
# -*- coding: utf-8 -*-
from transformers import GPT2TokenizerFast
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.chains.question_answering import load_qa_chain
from langchain.llms import OpenAI
import textract
Luego de importar las librerías tomamos nuestro PDF y le extraemos el texto con la función process
# convertimos el pdf a texto
doc = textract.process(r'C:\Users\HP\Desktop\chat_GPT\datos\Virus_Informaticos.pdf')
para que esta función funcione correctamente en nuestro Windows debemos tener instalado poppler y la ruta del mismo agregado al Path.
Lo siguiente que hacemos es guardar el texto que extraemos del PDF en un documento de texto y lo leemos
# guardamos el texto y reabrimos
with open('texto.txt', 'w', encoding="utf-8") as f:
f.write(doc.decode('utf-8'))
with open('texto.txt', 'r', encoding="utf-8") as f:
text = f.read()
luego creamos una función para contar los tokens esta función la pasaremos como argumento a nuestro text splitter que será el encargado de dividir nuestro texto en trozos
# creamos una funcion para contar los tokens
tokenizer = GPT2TokenizerFast.from_pretrained("gpt2")
def count_tokens(text: str) -> int:
return len(tokenizer.encode(text))
después de esto creamos nuestra base de datos de vectores, para hacer esto primero obtenemos nuestro modelo para crear los embeddings y creamos la base de datos pasándole los chunks y el modelo de embedding a FAISS.from_documents
# obtenemos el embedding model
embeddings = OpenAIEmbeddings()
# creamos la database de vectores
db = FAISS.from_documents(chunks, embeddings)
luego de esto lo que hacemos es pedirle al usuario que realice una pregunta y obtenemos los fragmentos relacionados con la pregunta que hizo el usuario gracias a un similarity search
# realizamos la busqueda por similaridad
query = input("realiza tu pregunta: ")
docs = db.similarity_search(query)
por último, creamos nuestra cadena Question answering que nos permite hacer preguntas y obtener respuestas, esta cadena la obtenemos con la función load_qa_chain que recibe como argumentos el modelo y el tipo de cadena, en este caso el tipo de cadena es stuff, este tipo de cadenas se recibe nuestros docs obtenidos con el similarity search como contexto
# creamos un QA chain que nos permite hacer preguntas en base a nuestros documentos
chain = load_qa_chain(OpenAI(temperature=0), chain_type="stuff")
print(chain.run(input_documents=docs, question=query))
al ejecutar nuestro código podemos ver la respuesta que nos da el modelo
Esta información es basada en nuestro documento PDF
Conclusión
Hemos visto como usar LangChain y lo poderoso que es este framework, LangChain tiene funcionalidades ya definidas y la posibilidad de implementar o agregarle nuevas funcionalidades lo que lo hace ideal para crear aplicaciones con LLM
Cuando nosotros escribimos nuestro código fuente en un lenguaje de alto nivel este al ser compilado es traducido a código maquina el cual es ejecutado por el procesador. Cuando realizamos ingeniería inversa tomamos un ejecutable ya compilado y realizamos el desensamblado del mismo para proceder con el análisis.
¿Qué es desensamblar?
Desensamblar es el proceso de traducir el código de máquina de un programa en lenguaje ensamblador. Es decir, el proceso de convertir el código de máquina en una representación legible por humanos, que es más fácil de entender y analizar que el código de máquina. Un desensamblador toma el archivo ejecutable del programa y lo analiza para identificar las instrucciones de código de máquina y su correspondiente representación en lenguaje ensamblador. El resultado es un archivo de texto legible por humanos que muestra el código ensamblador del programa. Es importante destacar que el proceso de desensamblar no siempre produce un código ensamblador idéntico al código fuente original, ya que el código de máquina puede ser optimizado y reordenado por el compilador durante la compilación. Por lo tanto, el código ensamblador producido por el desensamblador puede requerir cierta interpretación y análisis para comprender completamente su funcionamiento.
¿Qué es el lenguaje ensamblador?
El ensamblador (también conocido como «Assembly» en inglés) es un lenguaje de programación de bajo nivel utilizado para escribir programas que operan directamente en la arquitectura de una computadora. El ensamblador utiliza una sintaxis que está muy cerca del lenguaje de máquina, lo que permite al programador escribir instrucciones que se traducen directamente en códigos de máquina ejecutables por el procesador.
Antes de ver las instrucciones en ensamblador debemos conocer lo que son los registros, Los registros del procesador son pequeñas áreas de almacenamiento en la CPU que se utilizan para realizar operaciones aritméticas y lógicas, y para almacenar temporalmente datos y direcciones de memoria. Existen varios registros entre los cuales destacamos: registros de propósito general, registros de coma flotante y registros de propósito especifico.
Registros de propósito General (GPR)
Los registros de propósito general son utilizados para almacenar temporalmente datos y direcciones de memoria. Algunos de estos cumplen propósitos específicos en determinadas instrucciones. Entre los registros de propósito general para la arquitectura de 64 bits tenemos los registros RAX, RBX, RCX, RDX, RSI, RDI, RBP, RSP y los registros desde el R8 al R15
Registros de punto Flotante
Los registros de punto flotante son utilizados para realizar operaciones matemáticas con números de punto flotante en la arquitectura de 64 bits tenemos los registros de la serie XMM, YMM y ZMM
Registros de Propósito Especifico
Entre los registros de propósito especifico tenemos los registros RFLAGS y RIP. El registro RIP es utilizado para contener la dirección de la próxima instrucción que se va a ejecutar y el registro RFLAGS es utilizado para contener el estado de la CPU y contiene diferentes banderas que indican el resultado de las operaciones entre otras cosas
Si por ejemplo el resultado de una resta nos da cero el registro RFLAGS colocara la bandera que indica que el resultado es cero (Zero Flag) a 1 indicando que el resultado de la operación anterior fue cero. O si por ejemplo el resultado de la resta da un numero negativo la bandera del registro RFLAGS que indica que el resultado es un numero negativo (Sign Flag) será colocada a 1 en caso contrario es decir el resultado dio un numero positivo la bandera que indica que el resultado es negativo será colocada a 0
Instrucciones en ensamblador
Las instrucciones del lenguaje ensamblador son el conjunto de instrucciones que son interpretadas directamente por el procesador estas las podemos clasificar en, instrucciones de movimiento de datos, instrucciones de comparación, instrucciones aritméticas, instrucciones de control de flujo, instrucciones de llamada y retorno, instrucciones de manejo de pila, instrucciones lógicas y de desplazamiento de bits
instrucciones de movimiento de datos
Las instrucciones de movimiento de datos nos permiten mover desde la fuente al destino estas pueden ser de movimiento incondicional o movimiento condicional
Instrucciones de movimiento incondicional
Las instrucciones de movimiento incondicional son instrucciones que se encargan de mover datos desde la fuente al destino incondicionalmente es decir que no tienen en cuenta los FLAGS o banderas antes de mover entre estas instrucciones tenemos LEA, MOV y XCHG
MOV
La instrucción MOV nos permite mover datos desde fuente a destino en caso de que la fuente se encuentre entre corchetes (por ejemplo, modo de direccionamiento indirecto) se calculará la dirección y se moverá el contenido de la dirección a la fuente
sintaxis
mov destino, origen
ejemplo
mov eax, 1 ; mueve el valor 1 al registro EAX
mov ebx, eax ; mueve el valor de EAX a EBX
mov [memoria], eax ; mueve el valor de EAX a la dirección de memoria indicada
mov al, [ebx] ; mueve el byte almacenado en la dirección apuntada por EBX al registro AL
mov dword ptr [eax], 0 ; mueve el valor 0 a la dirección de memoria indicada por el registro EAX
LEA
La instrucción Lea (Load effective Address) es una instrucción utilizada para calcular la dirección efectiva, esta instrucción va a calcular la dirección del segundo operando (el operando fuente) y lo va a almacenar en el primer operando (destino) es decir calculará la dirección contenida entre corchetes y moverá la dirección no el contenido de la dirección
sintaxis
lea registro, dirección_de_memoria
ejemplo
lea ebx, [memoria] ; carga la dirección de memoria en EBX
lea eax, [ebx+4] ; carga la dirección de memoria desplazada por 4 bytes de la dirección almacenada en EBX en EAX
lea edx, [ebx+eax*2] ; carga la dirección de memoria desplazada por el doble del valor almacenado en EAX desde la dirección almacenada en EBX en EDX
XCHG
Exchange Esta instrucción intercambia los contenidos de registros/memoria con registros
sintaxis
xchg destino, origen
ejemplo
xchg eax, ebx ; intercambia el contenido de los registros EAX y EBX
MOVSX
La instrucción MOVSX (move sign extended) es una instrucción que mueve desde una fuente más pequeña a un destino más grande y el espacio sobrante lo rellena con el bit de signo de la fuente
sintaxis
movsx registro_destino, origen
ejemplo
movsx eax, byte ptr [memoria] ; mueve el byte almacenado en la dirección de memoria indicada a EAX y lo extiende a 32 bits
movsx ebx, word ptr [memoria] ; mueve la palabra almacenada en la dirección de memoria indicada a EBX y lo extiende a 32 bits
movsx edx, al ; extiende el valor del registro AL (8 bits) a 32 bits y lo mueve a EDX
MOVZX
La instrucción MOVZX (move zero extended) es una instrucción que mueve desde una fuente más pequeña (la cual puede ser un Word o byte) a un destino más grande y el espacio sobrante lo rellena con ceros
sintaxis
movzx registro_destino, origen
ejemplo
movzx eax, byte ptr [memoria] ; mueve el byte almacenado en la dirección de memoria indicada a EAX y lo extiende a 32 bits con ceros movzx ebx, word ptr [memoria] ; mueve la palabra almacenada en la dirección de memoria indicada a EBX y lo extiende a 32 bits con ceros movzx edx, al ; extiende el valor del registro AL (8 bits) a 32 bits con ceros y lo mueve a EDX
Instrucciones de movimiento condicional
Las instrucciones de movimiento condicional son instrucciones que verifican las banderas de estado o flags antes de mover en caso de que la condición necesaria para el movimiento no se cumpla es decir las banderas que esta verifica no están seteadas el movimiento no se realizará
instrucciones de comparación
las instrucciones de comparación realizan la comparación de dos operandos sin modificar ninguno de ellos, pero actualizando las banderas de estado dependiendo del resultado de la comparación entre las instrucciones de comparación tenemos TEST y CMP
TEST
La instrucción test realiza la operación AND entre el primer y segundo operando sin alterar ninguno, pero modificando las banderas de estado dependiendo del resultado de la operación AND
sintaxis
test destino, origen
ejemplo
test eax, ebx ; realiza la operación AND lógica entre EAX y EBX y establece las banderas según el resultado test al, 0xFF ; realiza la operación AND lógica entre el registro AL y el valor hexadecimal 0xFF, estableciendo las banderas según el resultado test [memoria], 0x10 ; realiza la operación AND lógica entre el valor almacenado en la dirección de memoria indicada y el valor hexadecimal 0x10, estableciendo las banderas según el resultado
CMP
La instrucción CMP (Compare) realiza una resta entre el primer y segundo operando (operando1-operando2) actualiza las banderas de estado y no modifica ninguno de los operandos
sintaxis
cmp operando1, operando2
ejemplo
cmp eax, ebx ; compara los valores de los registros EAX y EBX y establece las banderas según el resultado cmp al, 0xFF ; compara el valor del registro AL con el valor hexadecimal 0xFF y establece las banderas según el resultado cmp [memoria], ebx ; compara el valor almacenado en la dirección de memoria indicada con el valor del registro EBX y establece las banderas según el resultado
instrucciones aritméticas
las instrucciones aritméticas como su nombre lo indica nos permiten realizar operaciones aritméticas tales como la suma, resta, multiplicación o división
ADD
La instrucción ADD suma el operando fuente más el operando de destino y el resultado de la suma queda almacenado en el operando de destino
sintaxis
add destino, origen
ejemplo
add eax, ebx ; suma el valor del registro EBX al valor del registro EAX y almacena el resultado en EAX add [memoria], eax ; suma el valor del registro EAX al valor almacenado en la dirección de memoria indicada y almacena el resultado en esa dirección de memoria add al, 0x10 ; suma el valor hexadecimal 0x10 al valor del registro AL y almacena el resultado en AL
SUB
La instrucción SUB le resta al operando de destino la fuente (destino-fuente) y el resultado de la resta es almacenado en el operando de destino
sintaxis
sub destino, origen
ejemplo
sub eax, ebx ; resta el valor del registro EBX del valor del registro EAX y almacena el resultado en EAX sub [memoria], eax ; resta el valor del registro EAX del valor almacenado en la dirección de memoria indicada y almacena el resultado en esa dirección de memoria sub al, 0x10 ; resta el valor hexadecimal 0x10 del valor del registro AL y almacena el resultado en AL
MUL
Esta instrucción realiza la multiplicación sin signo del operando con el registro RAX y el resultado de la multiplicación es almacenado en RDX:RAX (la parte alta en RDX y la parte baja en RAX)
sintaxis
mul operando
ejemplo
mul eax ; multiplica el valor del registro EAX por el valor del registro EAX y almacena los 32 bits más significativos del resultado en EDX y los 32 bits menos significativos en EAX mul ebx ; multiplica el valor del registro EBX por el valor del registro EAX y almacena los 32 bits más significativos del resultado en EDX y los 32 bits menos significativos en EAX mul dword [memoria] ; multiplica el valor almacenado en la dirección de memoria indicada por el valor del registro EAX y almacena los 32 bits más significativos del resultado en EDX y los 32 bits menos significativos en EAX
IMUL
La instrucción IMUL realiza la multiplicación de números con signo y esta puede tener uno dos o tres operandos cuando esta tiene un operando se comporta similar a MUL pero en este caso multiplicando con signo el registro RAX por el operando y el resultado se almacena en el registro RDX:RAX. Con dos operandos multiplica la fuente por el destino y el resultado se almacena en la fuente. Con tres operandos multiplica el segundo operando con el tercer operando el cual debe ser una constante y el resultado lo almacena en el primer operando
imul eax, ebx ; multiplica el valor del registro EBX por el valor del registro EAX y almacena el resultado en EAX imul ecx, dword [memoria] ; multiplica el valor almacenado en la dirección de memoria indicada por el valor del registro ECX y almacena el resultado en ECX imul rax, rbx ; multiplica el valor del registro RBX por el valor del registro RAX y almacena el resultado en RAX
DIV
Esta instrucción realiza la división de números sin signo de los registros RDX:RAX (dividendo) entre el operando (divisor), el resultado es almacenado en el registro RAX y el residuo en el registro RDX
sintaxis
div operando
ejemplo
div ebx ; divide el valor del registro EDX:EAX (valor de 64 bits) por el valor del registro EBX y almacena el cociente en EAX y el resto en EDX div dword [memoria] ; divide el valor almacenado en la dirección de memoria indicada por el valor del registro EAX y almacena el cociente en EAX y el resto en EDX
IDIV
Esta instrucción realiza la división con signo de los registros RDX:RAX (dividendo) entre el operando (divisor), el resultado es almacenado en el registro RAX y el residuo en el registro RDX
sintaxis
idiv operando
ejemplo
idiv ebx ; divide el valor del registro EDX:EAX (valor de 64 bits) por el valor del registro EBX y almacena el cociente en EAX y el resto en EDX idiv dword [memoria] ; divide el valor almacenado en la dirección de memoria indicada por el valor del registro EAX y almacena el cociente en EAX y el resto en EDX
instrucciones de control de flujo
estas instrucciones nos permiten alterar el flujo del programa entre estas instrucciones tenemos las instrucciones de salto incondicional y salto condicional
instrucciones de salto incondicional
JMP
La instrucción JMP salta a la dirección de memoria especificada por el operando incondicionalmente es decir salta sin tener en cuenta las banderas o FLAGS
sintaxis
jmp destino
ejemplo
etiqueta: ; instrucciones jmp etiqueta ; salta de vuelta a la etiqueta ; más instrucciones
Instrucciones de salto condicional
Las instrucciones de salto condicional verifican determinadas banderas y si la condición se satisface es decir las banderas que chequea están seteadas salta a la dirección indicada por el operando, en caso contrario (la condición no se satisface) la instrucción no salta
instrucciones de llamada y retorno
las instrucciones de llamada y retorno nos permiten entrar y retornar de las funciones
CALL
La instrucción CALL salta a la dirección apuntada por el operando, pero antes coloca en el stack la dirección de retorno es decir la dirección siguiente a donde fue ejecutada
sintaxis
call subrutina
ejemplo
subrutina:
; instrucciones
ret ; retorna de la subrutina
call subrutina ; llama a la subrutina indicada y salta a la dirección de memoria donde comienza la subrutina
RET
La instrucción RET saltará a la dirección de retorno es decir la dirección colocada en el stack por la instrucción CALL
sintaxis
ret
ejemplo
subrutina:
; instrucciones
ret ; retorna de la subrutina
call subrutina ; llama a la subrutina indicada y salta a la dirección de memoria donde comienza la subrutina
instrucciones de manejo de pila
las instrucciones de manejo de pila nos permiten colocar y retirar valores de la pila o stack
PUSH
La instrucción PUSH coloca valores en el stack
sintaxis
push operando
ejemplo
push eax ; coloca el valor del registro eax en la pila push 10 ; coloca el valor 10 en la pila push dword [memoria] ; coloca el valor almacenado en la dirección de memoria "memoria" en la pila
POP
La instrucción POP retira valores del stack
sintaxis
pop destino
ejemplo
pop eax ; saca el valor de la cima de la pila y lo coloca en el registro eax pop dword [memoria] ; saca el valor de la cima de la pila y lo coloca en la dirección de memoria "memoria"
instrucciones lógicas
Las instrucciones Lógicas nos permiten realizar operaciones lógicas entre las cuales tenemos AND, OR, NOT, XOR
AND
La instrucción AND nos permite realizar la operación lógica AND entre el operando destino y fuente y el resultado de esta operación es almacenado en el operando de destino
sintaxis
and destino, origen
ejemplo
and eax, ebx ; realiza la operación lógica "AND" entre los valores de los registros eax y ebx, y almacena el resultado en eax and dword [memoria], 0xFF ; realiza la operación lógica "AND" entre el valor almacenado en la dirección de memoria "memoria" y la constante 0xFF, y almacena el resultado en la misma dirección de memoria
OR
La instrucción OR nos permite realizar la operación lógica OR entre el operando destino y fuente y el resultado de esta operación es almacenado en el operando de destino
sintaxis
or destino, origen
ejemplo
or eax, ebx ; realiza la operación lógica "OR" entre los valores de los registros eax y ebx, y almacena el resultado en eax or dword [memoria], 0x7F ; realiza la operación lógica "OR" entre el valor almacenado en la dirección de memoria "memoria" y la constante 0x7F, y almacena el resultado en la misma dirección de memoria
NOT
Esta instrucción realiza la negación del operando
sintaxis
not destino
ejemplo
not eax ; realiza la operación lógica "NOT" en el valor del registro eax, y almacena el resultado en eax not byte [memoria] ; realiza la operación lógica "NOT" en el valor almacenado en la dirección de memoria "memoria", y almacena el resultado en la misma dirección de memoria
XOR
La instrucción XOR nos permite realizar la operación lógica XOR entre el operando destino y fuente y el resultado de esta operación es almacenado en el operando de destino. Un uso frecuente de esta operación es colocar un registro a cero.
sintaxis
xor destino, origen
ejemplo
xor eax, eax ; coloca el registro eax a cero
xor eax, ebx ; realiza la operación lógica "XOR" entre los valores de los registros eax y ebx, y almacena el resultado en eax
xor byte [memoria], 0xff ; realiza la operación lógica "XOR" entre el valor almacenado en la dirección de memoria "memoria" y el valor 0xff, y almacena el resultado en la misma dirección de memoria
instrucciones de desplazamiento de bits
Las instrucciones de desplazamiento de bits como su nombre lo indica son utilizadas para desplazar bits, un uso muy frecuente es para manejar valores de campos de bits o para multiplicar o dividir entre potencias de 2
SHL y SAL
Las instrucciones SHL (Shift logical Left) y SAL (Shift artitmenical Left) desplazan os bits hacia la izquierda el número de veces indicado por la fuente, rellenando los nuevos lugares con ceros
sintaxis
shl destino, fuente
sal destino, fuente
ejemplo
mov eax, 0x00000001 ; mueve el valor hexadecimal 0x00000001 al registro eax shl eax, 1 ; desplaza los bits en eax un bit a la izquierda mov ebx, 0xffff0000 ; mueve el valor hexadecimal 0xffff0000 al registro ebx sal ebx, 4 ; desplaza los bits en ebx cuatro bits a la izquierda, realizando un desplazamiento aritmético
desplazar hacia la izquierda equivale a multiplicar por una potencia de dos
SHR
La instrucción SHR (Shift logical Right) desplaza los bits hacia la derecha el número de veces indicado por la fuente, rellenando los nuevos lugares con ceros
sintaxis
shr destino, fuente
ejemplo
mov eax, 0x12345678 ; coloca el valor 0x12345678 en eax shr eax, 4 ; desplaza 4 bits a la derecha
SAR
La instrucción SAR (Shift Aritmetical Right) desplaza los bits hacia la derecha el número de veces indicado por la fuente y rellena los nuevos lugares con el bit de signo que tenía el destino
sintaxis
sar destino, fuente
ejemplo
mov eax, 0xFFFF0000 ; coloca el valor 0xFFFF0000 en eax
sar eax, 16 ; desplaza 16 bits a la derecha
desplazar hacia la derecha equivale a dividir entre una potencia de dos
ROR y ROL
Las instrucciones ROR (Rotate right) y ROL (Rotate left) realizan una rotación de bits a la derecha e izquierda respectivamente
sintaxis
ror destino, fuente
rol destino, fuente
ejemplo
mov eax, 0x0F0F0F0F ; coloca el valor 0x0F0F0F0F en eax ror eax, 8 ; rota los bits de eax 8 posiciones a la derecha mov eax, 0x0F0F0F0F ; coloca el valor 0x0F0F0F0F en eax rol eax, 8 ; rota los bits de eax 8 posiciones a la izquierda
La lógica de programación es una habilidad fundamental que todo programador debe tener para escribir programas efectivos y eficientes. Se trata de la capacidad de analizar un problema, diseñar una solución y traducir esa solución en código. La lógica de programación implica una combinación de pensamiento creativo y analítico, y es esencial para el éxito en el desarrollo de software. Para mejorar la lógica de programación, es importante tener una buena comprensión de los fundamentos de la programación, practicar la resolución de problemas y tener la capacidad de analizar y dividir problemas complejos en partes más pequeñas. En última instancia, una buena lógica de programación es la clave para escribir software que funcione bien, sea fácil de entender y mantener, y resuelva problemas de manera efectiva.
¿Cómo mejorar la lógica de programación?
Aquí te presentamos algunos consejos muy efectivos para mejorar tu lógica de programación
Practica resolviendo problemas de programación: La práctica es fundamental para mejorar la lógica de programación. Resuelve problemas de programación en línea o a través de libros y ejercicios para fortalecer tu capacidad para analizar problemas y desarrollar soluciones.
Comprende los fundamentos de la programación: Es importante tener una buena comprensión de los conceptos fundamentales de la programación, como variables, estructuras de control de flujo (condicionales, ciclos), funciones, arreglos y objetos. Si no tienes una comprensión sólida de estos conceptos, tendrás dificultades para escribir programas complejos.
Analiza el problema antes de escribir código: Antes de empezar a escribir código, dedica tiempo a analizar el problema y entenderlo completamente. Considera diferentes soluciones y elige la mejor. Esto te permitirá evitar errores y encontrar soluciones más eficientes.
Divide el problema en partes más pequeñas: Una vez que hayas analizado el problema, divide el problema en partes más pequeñas. Esto hará que sea más fácil entender el problema y desarrollar una solución.
Utiliza pseudocódigo: El pseudocódigo es una herramienta útil para planificar el código antes de escribirlo. Escribir el código en un lenguaje parecido al natural, puede ayudarte a estructurar el código de manera más clara y organizada.
Utiliza estructuras de datos adecuadas: Asegúrate de utilizar las estructuras de datos adecuadas para el problema que estás tratando de resolver. Si utilizas la estructura de datos incorrecta, tu código puede ser ineficiente y difícil de entender.
Prueba tu código: Es importante probar tu código para asegurarte de que funciona correctamente. Realiza pruebas en diferentes situaciones y condiciones para garantizar que el código sea confiable y eficiente.
Lee y revisa el código de otros programadores: La lectura y revisión del código de otros programadores es una excelente manera de mejorar tu lógica de programación. Puedes aprender diferentes técnicas y enfoques que te ayudarán a mejorar tus habilidades.
Usar diagramas de flujo: Los diagramas de flujo pueden ayudar a visualizar el proceso de resolución de problemas y a identificar posibles problemas.
Analizar errores: Cuando se producen errores en el código, es importante analizarlos para comprender la causa y corregirlos. Este proceso puede ayudar a mejorar la lógica de programación.
Trabajar en equipo: Trabajar con otros programadores puede ayudarte a ver diferentes perspectivas y soluciones. Colaborar en proyectos de programación puede ayudarte a desarrollar habilidades de resolución de problemas y lógica de programación.
Utilizar IAs para mejorar la lógica de programación
Las inteligencias artificiales son uno de los avances tecnológicos que han tenido gran impacto en el mundo. Estas han sin duda alguna sido de gran utilidad en diversas áreas, pero si nos referimos al área de la programación han facilitado la labor de los programadores permitiéndoles ser más productivos y crear mejores códigos. Esta puede ser útil para mejorar la lógica de programación de las siguientes maneras: Las Inteligencias artificiales cuentan con algoritmos de aprendizaje automático, estos pueden ayudar a analizar el código y detectar patrones, errores y oportunidades de optimización. Al trabajar con estos algoritmos, puedes aprender a identificar y solucionar problemas de manera más eficiente. Un ejemplo de esto es el siguiente. partiendo del siguiente código:
# programa q dado 5 numeros enteros calcula cual es mas cercano al primero
# pedimos los numeros a ingresar
num1=int(raw_input('ingresa el numero principal'))
num2=int(raw_input('ingresa el numero uno'))
num3=int(raw_input('ingresa el numero dos'))
num4=int(raw_input('ingresa el numero tres'))
num5=int(raw_input('ingresa el ultimo numero'))
# creamos una funcion para devolver el valor absoluto ya q abs no quiere servir
def absoluto(num):
if num < 0:
num=-num
else:
num=num
return num
# calculamos que distancia hay de el numero principal a los demas
distancianum2=absoluto(num1-num2)
distancianum3=absoluto(num1-num3)
distancianum4=absoluto(num1-num4)
distancianum5=absoluto(num1-num5)
# calculamos cual es la menor distancia
candidato=distancianum2
numeroMenor=num2
if distancianum3 < candidato:
candidato=distancianum3
numeroMenor=num3
if distancianum4 < candidato:
candidato=distancianum4
numeroMenor=num4
if distancianum5 < candidato:
candidato=distancianum5
numeroMenor=num5
# imprimimos los resultados
print 'el numero mas cercano al %d es %d' % (num1, numeroMenor )
nos dirigimos a la página de chatgpt y pegamos nuestro código al presionar enter esta herramienta nos comenta que el código tiene errores de sintaxis debido a que el código fue escrito para Python 2.x la cual es una versión antigua de Python y nos muestra el código corregido
Este es el código corregido por la herramienta:
# pedimos los numeros a ingresar
num1 = int(input('ingresa el numero principal: '))
num2 = int(input('ingresa el numero uno: '))
num3 = int(input('ingresa el numero dos: '))
num4 = int(input('ingresa el numero tres: '))
num5 = int(input('ingresa el ultimo numero: '))
# creamos una funcion para devolver el valor absoluto ya que abs no quiere funcionar
def absoluto(num):
if num < 0:
num = -num
else:
num = num
return num
# calculamos que distancia hay del numero principal a los demas
distancianum2 = absoluto(num1 - num2)
distancianum3 = absoluto(num1 - num3)
distancianum4 = absoluto(num1 - num4)
distancianum5 = absoluto(num1 - num5)
# calculamos cual es la menor distancia
candidato = distancianum2
numeroMenor = num2
if distancianum3 < candidato:
candidato = distancianum3
numeroMenor = num3
if distancianum4 < candidato:
candidato = distancianum4
numeroMenor = num4
if distancianum5 < candidato:
candidato = distancianum5
numeroMenor = num5
# imprimimos los resultados
print('el numero mas cercano al %d es %d' % (num1, numeroMenor))
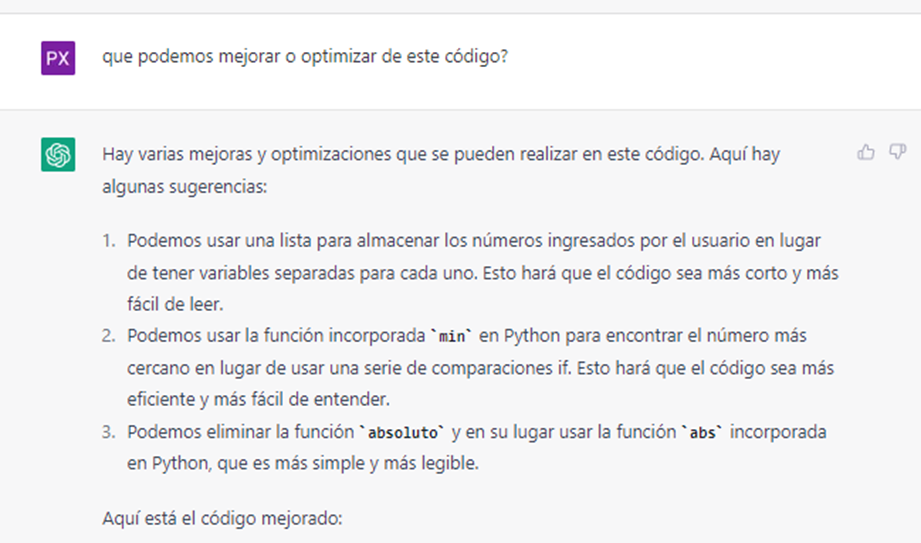
cómo podemos apreciar la herramienta ha portado el código de Python 2.x a Python 3.x ahora iremos un paso más allá y le pediremos a la herramienta que nos diga que se puede mejorar del código
# Pedimos al usuario que ingrese los números
numeros = []
for i in range(5):
num = int(input(f"Ingrese el número {i+1}: "))
numeros.append(num)
# Encontramos el número más cercano al primer número ingresado
numero_cercano = min(numeros[1:], key=lambda x: abs(x - numeros[0]))
# Imprimimos los resultados
print(f"El número más cercano a {numeros[0]} es {numero_cercano}")
la herramienta nos retorna un código mucho mejor estructurado, legible, optimizado y completamente funcional.
Existen también varias plataformas de entrenamiento de programación en línea que utilizan la inteligencia artificial para evaluar y brindar retroalimentación sobre el código escrito. Estas plataformas pueden ayudarte a comprender cómo funciona tu código y cómo mejorarlo. Unos ejemplos de dichas plataformas son:
Codecademy: Una plataforma interactiva que enseña programación de una manera amigable para principiantes. Codecademy utiliza ejemplos y proyectos prácticos para ayudar a los estudiantes a aprender a programar, y utiliza la IA para evaluar el código y brindar retroalimentación inmediata.
HackerRank: Una plataforma de entrenamiento de programación que ofrece desafíos de programación y competencias de codificación en línea. HackerRank utiliza la IA para evaluar el código y proporcionar comentarios sobre cómo mejorar el rendimiento y la eficiencia.
LeetCode: Una plataforma que ofrece una amplia variedad de preguntas y desafíos de programación que cubren múltiples áreas de programación y habilidades técnicas. LeetCode utiliza la IA para evaluar el código y proporcionar retroalimentación detallada sobre la lógica y el rendimiento del código.
Codewars: Una plataforma de entrenamiento de programación que ofrece una variedad de desafíos de codificación en línea. Codewars utiliza la IA para evaluar el código y proporcionar retroalimentación instantánea.
Además, las Inteligencias artificiales pueden sugerir soluciones para problemas específicos de programación. Al trabajar con estas recomendaciones, puedes aprender a aplicar soluciones prácticas y desarrollar una mejor lógica de programación.
También te pueden responder preguntas especificas del lenguaje como por ejemplo puedes preguntar que función se usa en c++ para comparar dos strings o como se crea un array en java
Ejemplo de Lógica de Programación
Crea un programa que implemente un cifrado de sustitución.
seudocódigo:
1. Pedir al usuario que ingrese una cadena de texto a cifrar. 2. Crear un diccionario que contenga las letras y sus correspondientes sustitutos. 3. Crear una cadena de texto vacía para almacenar la versión cifrada de la cadena de texto original. 4. Recorrer cada letra en la cadena de texto original: y agregar su valor sustituto al resultado cifrado. 5. Mostrar el resultado cifrado al usuario.
En conclusión, mejorar tu lógica de programación es fundamental para convertirte en un programador exitoso. A través de la práctica, el estudio y la experiencia, puedes desarrollar habilidades que te permitirán resolver problemas de manera eficiente y desarrollar soluciones innovadoras. Además, la inteligencia artificial y otras tecnologías pueden ser herramientas útiles para mejorar tu lógica de programación y acelerar tu proceso de aprendizaje. Recuerda que la programación es un proceso continuo de aprendizaje y mejora, y siempre hay oportunidades para mejorar tu habilidad y convertirte en un programador de clase mundial.
Este ejercicio se trata de un Stack based buffer overflow y el objetivo es ejecutar calc.exe, sin más que decir empecemos con el análisis
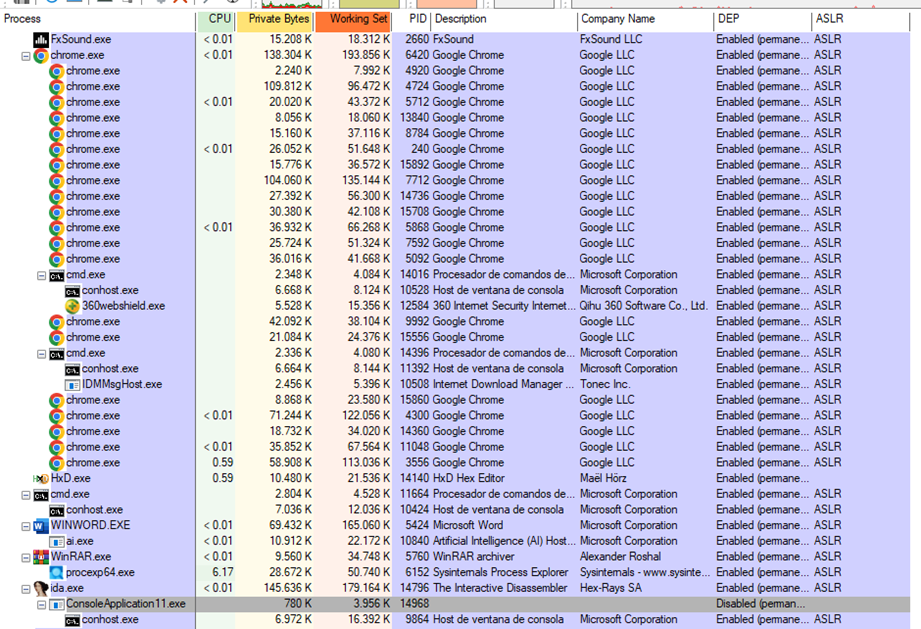
Abrimos nuestro ejecutable con el depurador de ida y parados en un breakpoint podemos cerciorar con process explorer que este no cuenta con protecciones como DEP y ASLR
Ahora analicemos el mismo en IDA
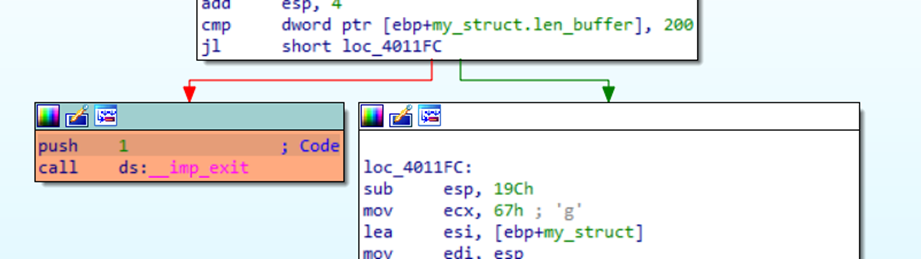
Parados en la función main vemos que lo primero que hace es verificar si el numero de argumentos pasados por consola es dos o mayor a dos
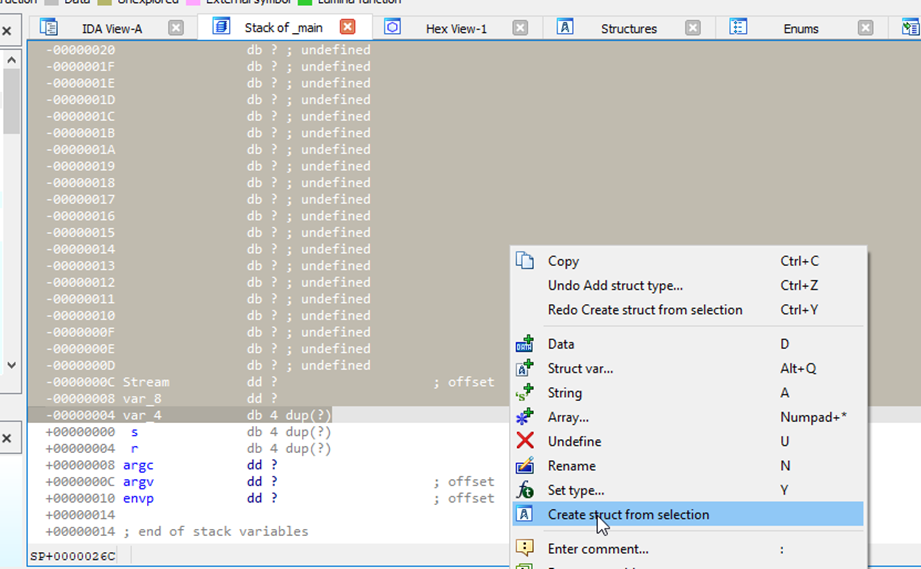
En caso de que la condición no se cumpla imprimirá en consola bye y saldrá del programa y en caso de que la condición se cumpla llamara a un método constructor pasando como parámetro Destination, renombremos esta función a constructor, Como podemos apreciar Destination es una variable del stack, veamos que hace el constructor
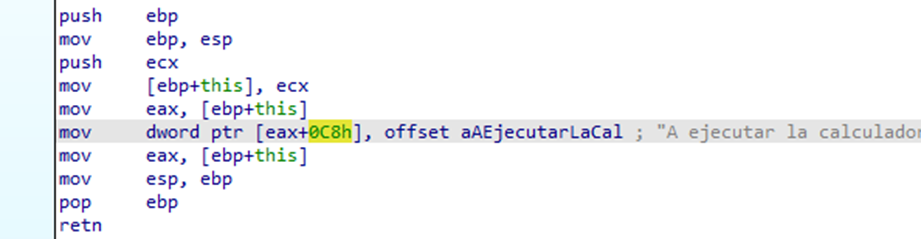
Esta toma el this y en el offset 0xc8 coloca el puntero a la string “A ejecutar la calculadora de nuevo…”, creemos la estructura Hasta ahora no sabemos el tamaño de la estructura, pero podemos tomar todo el tamaño del stack y si es necesario corregimos más adelante, así que lo que aremos será resaltar toda esa zona del stack y presionaremos Create Struct from selection
Ahora si abrimos view->open Subview->Structures
Podemos ver y editar nuestra estructura, así que vallamos al offset 0xc8 de nuestra estructura y nombrémoslo str_aEjecutar
Presionamos la tecla D para cambiar el tipo varias veces hasta que quede de tipo DD
Luego presionamos la N para cambiar el nombre a str_aEjecutar
Ya que hemos creado nuestra estructura podemos regresar a nuestro constructor
Con el offset de la estructura seleccionado apretamos T y seleccionamos nuestra estructura
Nos queda de esta forma, regresemos al main para continuar con nuestro análisis
Lo siguiente que hace es guardar el puntero a system en un miembro de la estructura renombremos Destination a my_estruct y var_8 a ptr_system
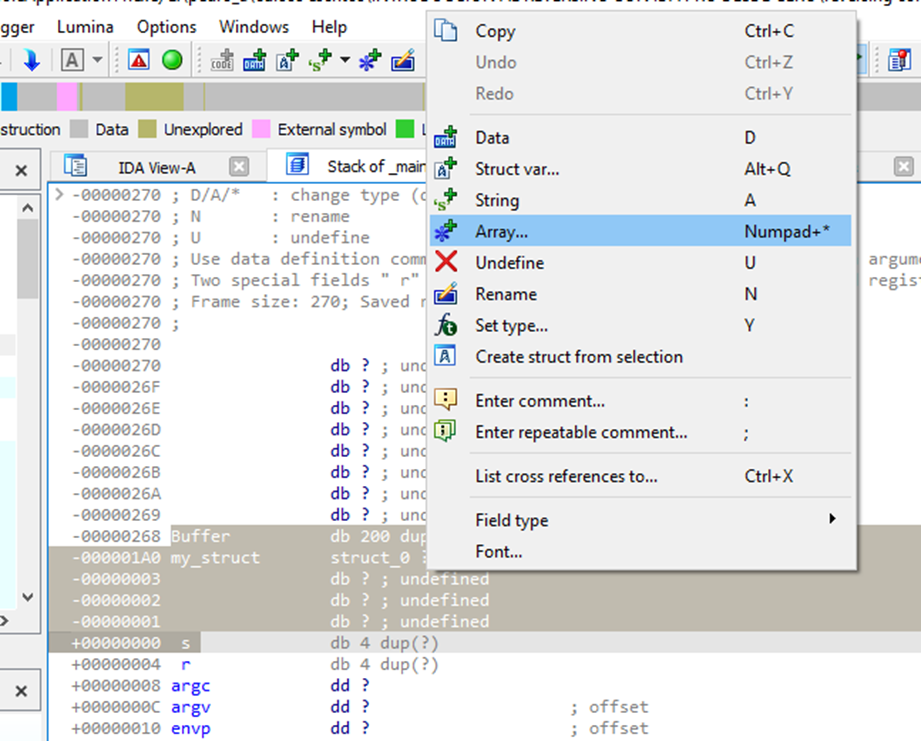
Luego con memset va a colocar a cero dos buffers de tamaño 0xc8 el primero en el offset cero y el segundo en el offset de var_d4, editemos nuestra estructura Renombramos nuestros miembros a bufer1_200 y buffer2_200 y los convertimos en array de tamaño 0xc8 con clic derecho array
Array size 0xc8 y presionamos ok
Nuestra estructura nos quedó de esta forma
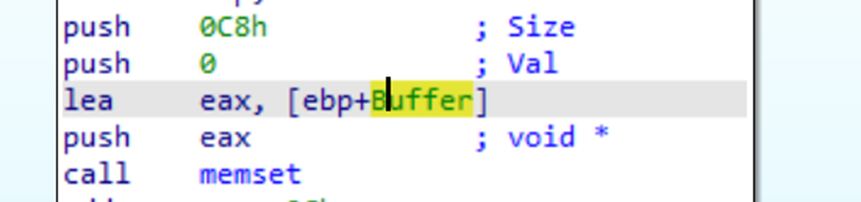
Luego toma un buffer y lo inicializa a ceros este tiene un tamaño también de 0xc8 o 200 decimal
Luego lo que hace es copiar el argumento pasado por consola y copiarlo al buffer1_200 y luego usa esa string como un nombre de archivo que se le pasa a fopen en modo lectura así que renombraremos buffer1_200 a filename, como usa strcpy que es una función insegura y no ha realizado ningún chequeo aquí podemos overflodear, pero sigamos analizando
Guarda el handle del archivo en my_struct.Stream y chequea si es cero, en caso de serlo imprime que no se pudo leer el archivo y sale, en caso contrario imprime la string str_aEjectar con lo que imprime “A ejecutar la calculadora de nuevo…” luego lee 0xc8 bytes del archivo en buffer que como es del tamaño correcto no hay overflow
Con strlen saca el largo del buffer lo guarda en var_4 y lo imprime, cambiemos el nombre de var_4 a len_buffer
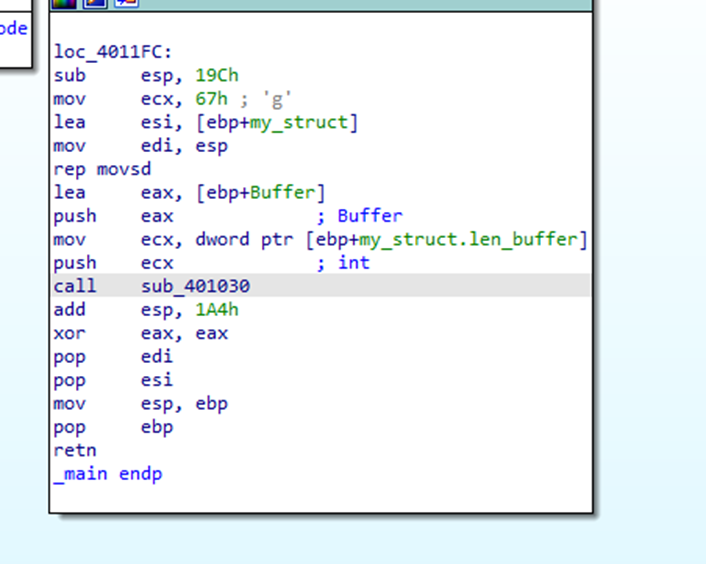
Luego verifica el largo del buffer con 0xc8 si no es menor sale, este chequeo solo verifica el contenido del archivo hasta que encuentra un cero, en caso de que pase el chequeo llama a una función sub_401030 pasándole como argumentos el largo del buffer, el puntero al buffer, y una copia de my_struct en el stack. Veamos que hace esta función
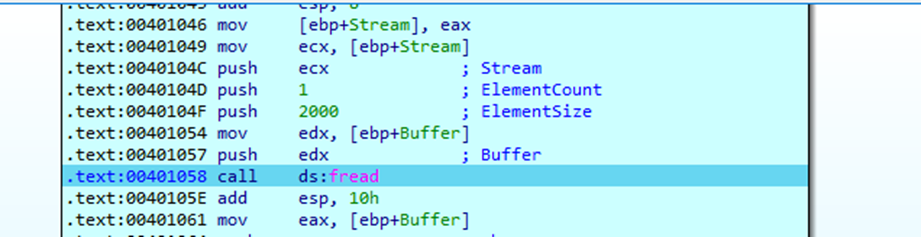
Esta función lo que hace es tomar el filename (primer campo de la estructura) y pasarlo a fopen el cual lo abre en modo lectura binaria, luego lee 0x7d0 (2000) bytes del archivo y los almacena en buffer el cual es de 0xc8 (200), algo que se me olvidaba mencionar es que los números en Hexa los podemos convertir en decimales seleccionándolos y presionando la letra H
Aquí vemos que el buffer que es de 200 se escribirán 2000 bytes así que tenemos un overflow, luego imprimirá el buffer y retornará.
Cuando retorna de esta función retorna del main y nuestro programa terminará
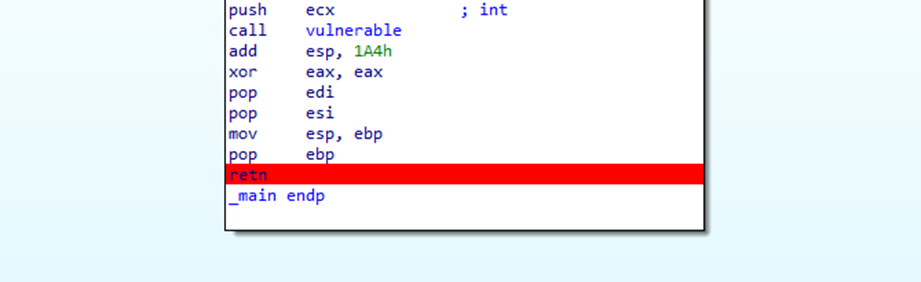
Renombremos esta función a vulnerable
Ahora veamos cómo podemos explotar esta función vulnerable, para esto tenemos que tener en cuenta los chequeos que realiza el programa y cumplirlos todos para poder llegar a esa función
Primero debemos pasarle como argumento el nombre del archivo a leer
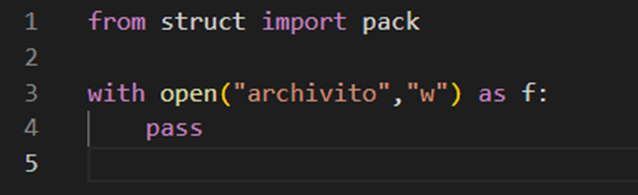
Este archivo debe tener una string de menos de 200 bytes. Creemos nuestro archivo con Python, así que abramos nuestro editor favorito y creemos un script de Python para explotar este programa
Lo primero que hacemos será importar pack y creamos un archivo en modo escritura, pero ¿Qué escribiremos?, lo que tenemos que hacer es determinar en qué offset se encuentra nuestro retorno, para que al pisarlo con determinado valor el programa salte a ejecutar la dirección que nosotros controlamos, generalmente lo que se hace es pisar el ret por un jmp esp, call esp, o push esp ret o cualquier instrucción que salte a ejecutar el stack y en este tendremos nuestra shellcode la cual se ejecutará. Bien teniendo esto claro pasemos a determinar el offset de nuestro ret
En la pestaña del stack de nuestra función main seleccionamos desde el inicio del buffer que vamos a overflodear hasta el estored ebp (s) presionamos array y este nos mostrará la cantidad de bytes necesarios para pisar el ret
En este caso 620 También podemos encontrar el offset mediante el uso de patterns esta técnica consiste en llenar el buffer con cadenas de caracteres únicos y al final con el debugger ver el valor de eip y buscar ese valor en la cadena y así determinar el offset exacto donde se pisa eip
En nuestro script lo que hicimos fue crear una variable llamada primeraComp que contiene 100 Aes y un null terminator esto con el objetivo de pasar la comparación que verifica que strlen sea menor a 200, lo que hace strlen es contar todos los caracteres y parará cuando encuentra el cero, luego lo que hicimos es crear una variable junk que contiene una formulita que desglosaremos a continuación
sta primera parte agrega a junk el contenido de primeraComp que es nuestras 100 Aes
Luego en el paréntesis se calcula (620-len(primeraComp)) esto lo hacemos para obtener la diferencia es decir queremos saber el numero de Aes faltantes para que en total tener 620 y estas Aes las concatenamos con las anteriores teniendo en total 620 bytes el cual corresponde a 100 Aes un NULL y EL resto de Aes
Luego creamos una variable llamada eip el cual contiene el valor que pisara nuestro registro eip
Por último, lo que hacemos es escribir nuestro junk+eip que corresponde a los 620 bytes junk y eip será nuestro valor controlado al cual saltaremos, depuremos
En la pestaña debugger->switch debugger seleccionamos local Windows debugger
Damos clic en debugger->Process options
Y en parameters le colocamos el parámetro que en este caso es el nombre del archivo
Luego de haber ejecutado nuestro script de Python colocamos el archivo generado en la misma carpeta que el ejecutable, ponemos un breakpoint en main y presionamos el botón de start
Pasa satisfactoriamente la primera comparación
pasa la comparación del largo del buffer
y se dirige a ejecutar nuestra función vulnerable, presionamos step into
Dentro de la función abre el archivo nuevamente
Lee los 2000 bytes, en este punto la dirección de retorno de la función main debe estar pisada por 0x41424344 veamos
Retorna de la función vulnerable y se acerca al ret de main, avancemos hasta estar parados en el ret
Parados en el ret vemos que este retornará a 0x41424344 con lo que satisfactoriamente controlamos la dirección de retorno, ahora ya que controlamos la dirección de retorno coloquemos nuestra shellcode en el stack y retornemos a un jmp esp para ejecutar nuestra shellcode
Nuestra shellcode es muy sencilla lo que hace es mover a edx un puntero a una zona escribible y en esta escribir “calc” (clac esta al revés por ser Little endian) luego mueve a eax el offset de la iat de system le pasa como parámetro nuestro puntero a calc y llama a system(“calc”).
Lo siguiente que debemos hacer es saltar a ejecutar el stack, pero en este caso no tenemos ninguna instrucción jmp esp o similares ¿Qué podemos hacer?
Si bajamos un poco en el stack podemos ver varios punteros al stack, lo que podemos hacer es pisar el ultimo byte con el offset al inicio de nuestra shellcode, el puntero esta en 19ff60 y nuestro ret está en 0019FF28 , calculemos el desplazamiento para pisar este valor:
0x19FF60-0x19FF28 = 0x38 = 56
56 bytes, pero estos no pueden ser cualquier valor ya que si intentamos retornar a una dirección invalida nos lanzara una excepción una solución es colocar direcciones a ret de tal manera que retorne y retorne sucesivamente hasta llegar al valor, hagámoslo
Hemos hecho nos cambios a nuestra shellcode, des pues de nuestro buffer colocamos nuestra shellcode, seguido de Aes hasta completar 620 y luego 13 rets y por ultimo los bytes que pisa el puntero al stack con el offset de nuestra shellcode, si ejecutamos
Podemos ver que nuestra shellcode es ejecutada, depuremos
Colocamos un breakpoint en el return del main y ejecutamos
Parados en el ret vemos en el stack que el programa retornara a 0x401077 que es una instrucción ret
En esta imagen podemos apreciar la instrucción a la cual retornará
Luego de retornar varias veces en el stack queda el puntero al stack qué le pisamos los últimos bytes para que apuntara a nuestra shellcode al presionar ret se ejecutará nuestra shellcode
Nuestra shellcode escribe en 0x4030D0 calc y luego llama a system(“calc”) ejecutando así nuestro calc
Debugging o depuración es el proceso de encontrar bugs o errores en el programa, en este identificamos y aislamos las causas del error. Este puede llevase a cabo de diferentes maneras entre las cuales tenemos software testing, revisión del código o mediante herramientas como debuggers
¿Qué es un debugger?
Un debugger es una herramienta que nos permite depurar un programa en estos podemos ver instrucción por instrucción, alterar el flujo de ejecución, ver los valores de las distintas variables y editarlos, colocar puntos de interrupción o breakpoints. Los depuradores nos permiten ver cómo se comporta el programa mientras es ejecutado
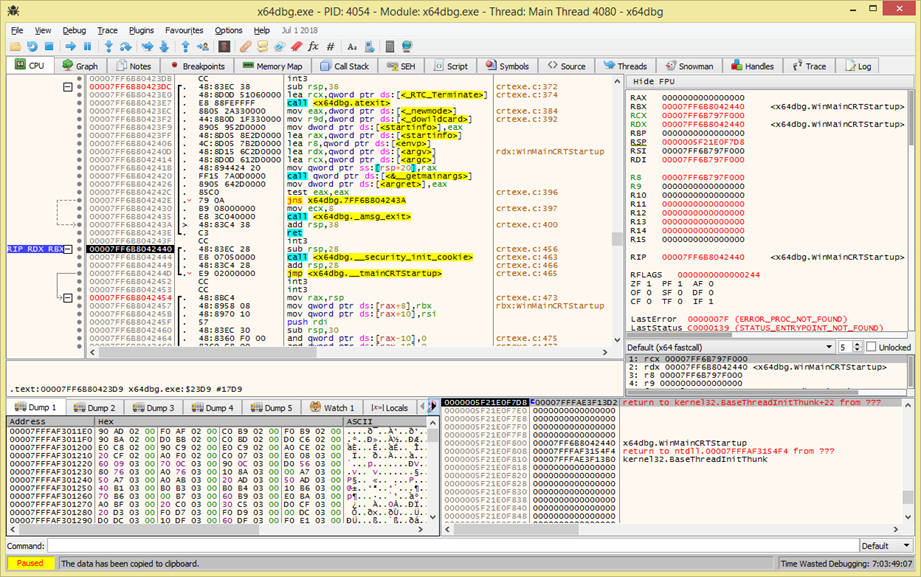
Conociendo las partes de un debugger
En esta parte procederemos a conocer las diferentes partes que puede tener un debugger tomando como ejemplo un debugger muy utilizado llamado x64dbg, el objetivo de esta parte es familiarizarse no solo con este depurador sino entender las diferentes partes para tener un conocimiento general que nos puede servir para cualquier depurador. Algo a tener en cuenta es que algunas de las cosas incluidas en un depurador quizás no estén incluidas en otro, pero hay elementos que son comunes de depurador a depurador
Este es nuestro depurador, lo primero que haremos será cargar un archivo ejecutable para depurarlo, para hacer esto presionamos archivo->abrir
Entre las otras opciones que tenemos están vincular que nos permite depurar un proceso que se encuentra corriendo actualmente, cambiar el comando empleado que nos permite pasarle argumentos al proceso
Una vez cargado nuestro programa en el depurador este para por defecto en el breakpoint del sistema y nos rellenara las diferentes partes con distinta información que procederemos a aclararlos a continuación
Desensamblado
En esta parte se nos muestra el código ensamblador de nuestro ejecutable, en esta parte podemos ver las instrucciones que el programa va ejecutando, podemos colocar breakpoints en la dirección que queramos y también podemos alterar el flujo de ejecución del mismo
Registros
En esta parte podemos ver y modificar los valores de los diferentes registros incluyendo las banderas de estado
Variables Locales
En esta parte nos muestra las variables locales de la función que estamos depurando actualmente y también nos da la opción de seleccionar la convención de llamada de la función
Aclaraciones
En esta parte se nos mostraran aclaraciones como por ejemplo el contenido de un puntero
Volcado de memoria
En esta parte tenemos el volcado de memoria es decir el contenido de la memoria, esta parte la usamos cuando queremos ver el contenido de cierta zona de memoria
Stack
En esta parte tenemos el contenido del stack, que como sabemos es la zona destinada para guardar nuestras variables locales, argumentos, registros salvados entre otra información
En la pestaña breakpoints tenemos todos los breakpoints o puntos de interrupción que hemos colocado, por defecto el depurador nos coloca un breakpoint en el entry point del programa y nos aclara que parará una sola vez
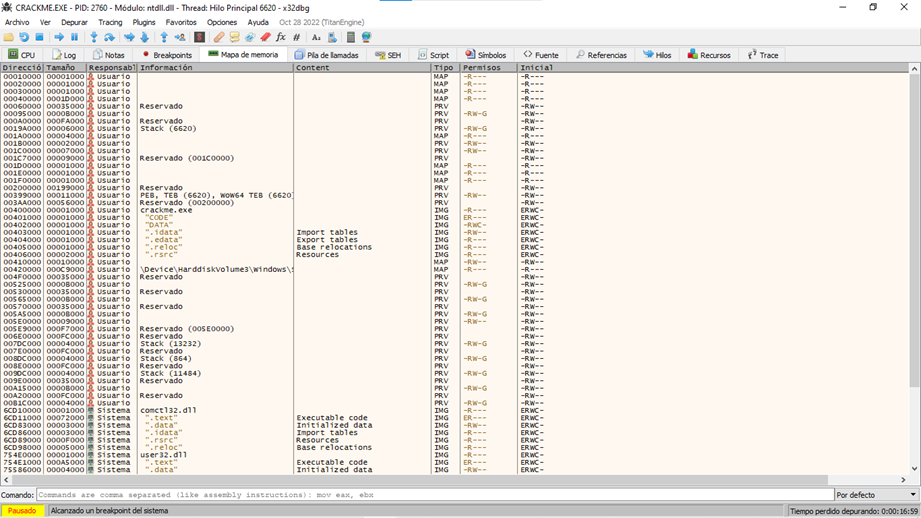
En la pestaña mapa de memoria podemos ver las diferentes secciones del ejecutable, su dirección de inicio y final, así como también las secciones de las diferentes dlls, memoria reservada dinámicamente y los permisos de estas
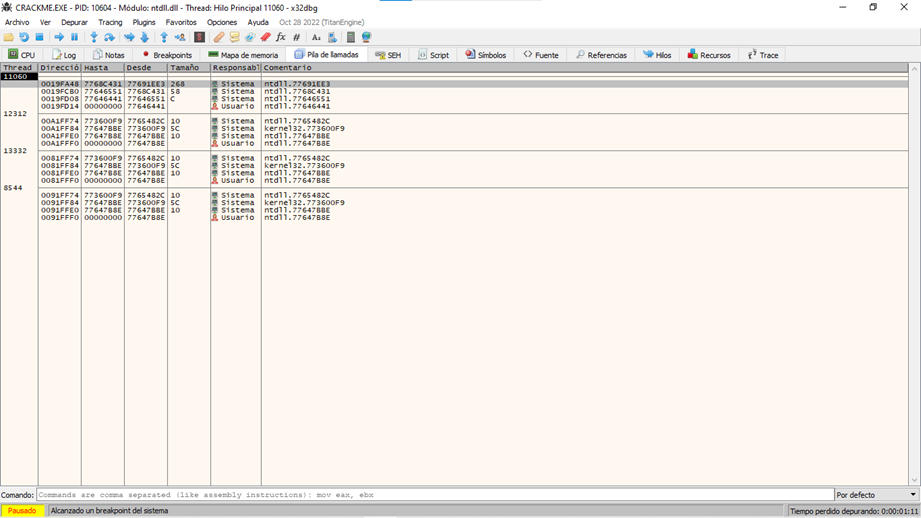
En la pestaña pila de llamadas tenemos la pila de llamadas es decir las funciones que han sido llamadas para llegar a la función actual, de primero tenemos la función actual y bajando tenemos los callers
Una vez familiarizados con el debugger procederemos a aprender a como depurar nuestros programas, para esto debemos aprender a como tracear, también debemos aprender a colocar puntos de interrupción y los diferentes puntos de interrupción que tenemos a nuestra disposición, además debemos aprender a buscar referencias y otra información que nos puede ser de utilidad.
Con el objetivo de ilustrar esto procederemos a realizar el análisis del crackme de cruehead, en este articulo no veremos la solución del mismo solo lo tomaremos como ejemplo para aprender a usar nuestro depurador
El primer paso será abrir nuestro crackme en el depurador y una vez abierto nos parará por defecto en el breakpoint del sistema
si queremos cambiar este comportamiento lo podemos hacer en opciones->preferencias y en la pestaña eventos podemos seleccionar solamente el breakpoint en el punto de entrada o entry point, esto hará que el programa pare en el entry point
Resaltado en la imagen superior tenemos los comandos que nos permiten, reiniciar el programa, detenerlo, correrlo, pausarlo y tracearlo, procederemos a explicar cada uno a continuación
Reiniciar
Reinicia el proceso que está siendo depurado actualmente
Detener
Detiene el proceso que está siendo depurado actualmente
Ejecutar
Ejecuta el programa hasta que este finaliza o encuentra un breakpoint
Pausar
Pausa la ejecución del programa
Step into
Ejecuta la instrucción entrando a cada uno de los calls
Step over
Ejecuta la instrucción sin entrar a los calls, los calls se ejecutan por completo, pero no se muestra el código dentro de estos
Trace Into y Trace Over
Inicializar el traceado que lo que hace es ejecutar las instrucciones recordándolas y se detiene cuando se cumple determinada condición
Ejecutar hasta el retorno
Ejecuta el contenido de la función actual hasta que llega al fin de esta (el retorno)
Ejecutar hasta el código de usuario
Ejecuta todo el código del sistema y se detiene cuando llega nuevamente al código de usuario
Breakpoints
Los breakpoints o puntos de interrupción los utilizamos cuando queremos parar en determinada instrucción o código que nos interesa, existen varios tipos de breakpoints como lo son de memoria, de hardware y software
Memory Breakpoints
Los breakpoints de memoria nos permiten detener la ejecución del programa cuando se accede a determinada zona de memoria estos pueden parar en acceso ya sea para lectura o escritura, solo en lectura, solo en escritura o en ejecución
Hardware Breakpoints
Los hardware breakpoints son llevados a cabo mediante registros de depuración en el procesador podemos colocar un máximo de 4 breakpoints de este tipo y las condiciones de estos pueden ser de en acceso, en lectura, escritura o ejecución
Software Breakpoints
Este tipo de breakpoint lo colocamos cuando queremos parar en determinada instrucción, cuando colocamos este tipo de breakpoint el depurador cambia la instrucción por un int3 que hace que el programa se detenga ahí pero estos pueden llegar a ser detectados por el programa fácilmente, los breakpoints de software paran en ejecución pero x64dbg soporta breakpoints por software condicionales un ejemplo de esto puede ser parar si determinado registro tiene determinado valor como por ejemplo eax==0x1234
Retomando a el ejemplo del crackme lo primero que hacemos será correr el mismo en el debugger e intentar buscar referencias a cadenas que puedan ser de nuestro interés o también podemos parar en el momento en que se lee nuestro username y serial
Una vez abierto presionamos register
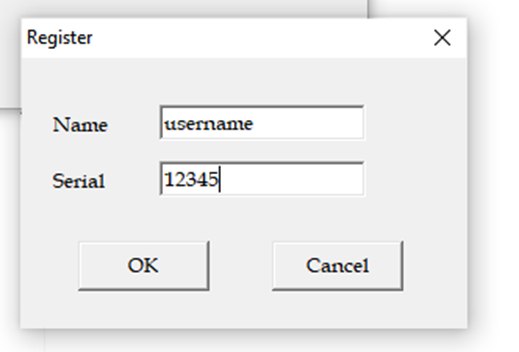
nos abre esta ventanita que nos pide nombre de usuario y serial coloquemos username y 12345
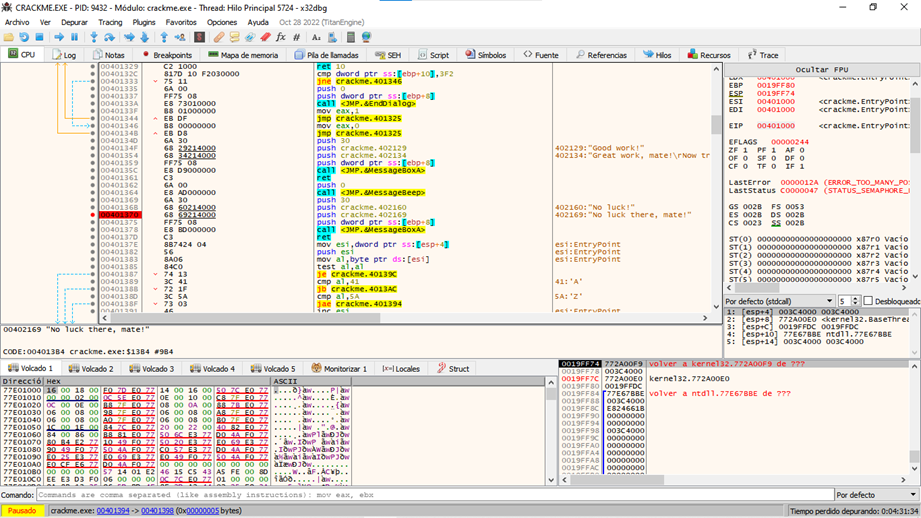
Nos abre esta ventanita que nos indica que fue invalido, tratemos de ver si encontramos referencias a esta string en el debugger y analizar el código en busca de la comparación que decide cuando mostrar o no esta ventanita
Presionamos en el área del desensamblado clic derecho buscar en->módulo actual->referencias a cadena
Vemos que tuvimos suerte y encontramos dos referencias a la cadena “no luck there, mate!” coloquemos un breakpoint en ambas direcciones
Ahí colocamos nuestros breakpoints en las dos referencias, y nos damos cuenta que en una de las referencias esta muy cerca una referencia a la cadena que puede ser nuestro chico bueno, nos ayudamos con un plugin llamado xAnalyzer, una vez instalado el plugin de a cuerdo a las instrucciones de github
Damos clic derecho xAnalyzer analyze module
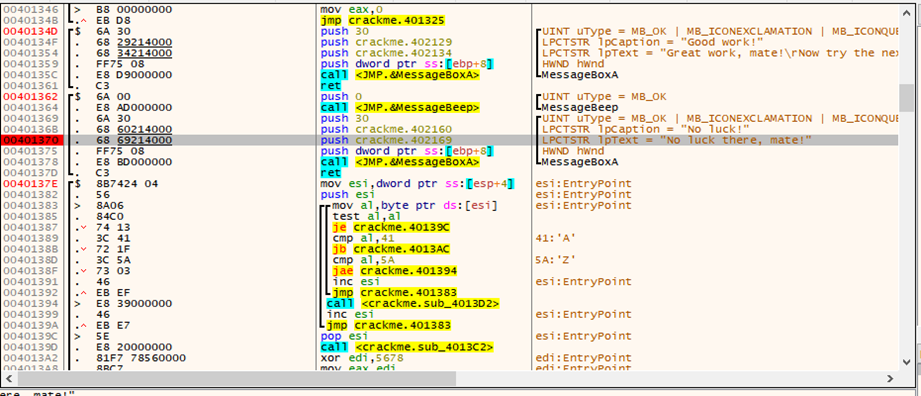
Este plugin hace un gran trabajo resaltándonos el inicio de las funciones ciclos y demás, vemos que nuestra referencia a nuestra string “no luck there, mate!” es usada por un mensaje box en una función que empieza en 0x401362 y si nos fijamos en la otra referencia
Está dentro de otra función que empieza en 0x40137e esta función hace determinadas comparaciones y ciclos y si no le gusta nos manda al chico malo, ahora busquemos referencias a el código que llama a estas funciones, lo primero que haremos es en el inicio de cada una de estas funciones (me refiero a las funciones que llaman a nuestra cadena)
Posicionados en la dirección que queremos encontrar referencias damos clic derecho->encontrar referencias a-> dirección seleccionada
Nos dirigimos a la dirección y colocamos un breakpoint
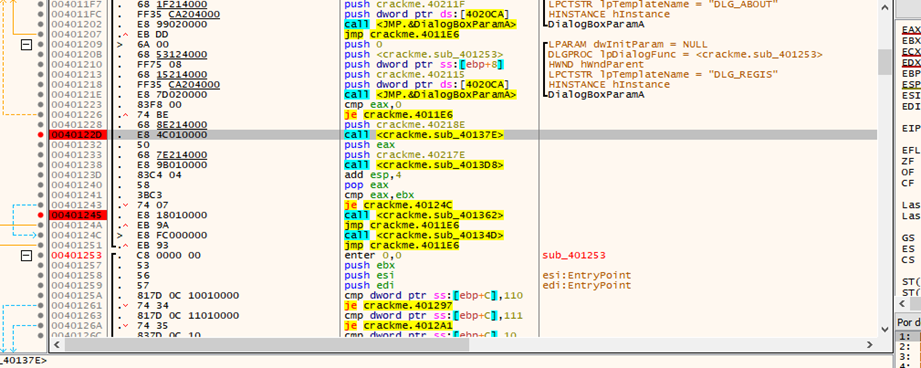
Una vez hecho esto con las dos referencias reiniciamos nuestro programa
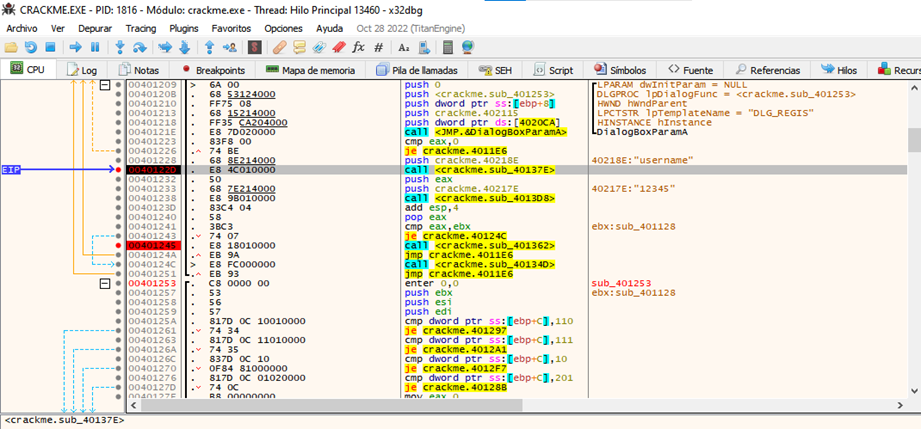
Colocamos un username y un serial y al dar ok se detiene en nuestro breakpoint
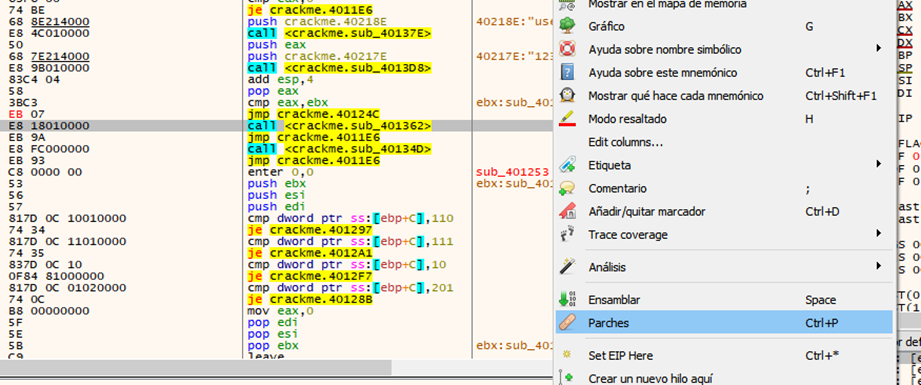
Una vez detenidos podemos ver que va a pasar nuestro username y nuestro serial a dos funciones, la función en la que le pasa el username es la función que realizaba unas comparaciones y bucles y si algo no le gustaba nos mostraba el mensaje de chico malo, al salir de estas funciones en la dirección 0x401241 realiza una comparación que si eax es igual a ebx llama a la función 0x40134d que si nos fijamos cual es
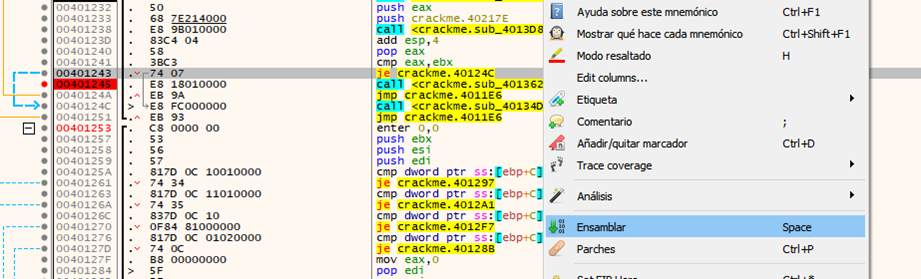
Nos damos cuenta que es la función que nos manda el cartel de felicitaciones, así que lo que haremos es forzar el salto para que siempre nos mande al cartel de felicitaciones a esto se le conoce como parchear
Posicionados sobre el salto decisivo damos clic derecho->ensamblar o presionamos espacio
Cambiaremos el je (salta si es igual) por un jmp (salta siempre)
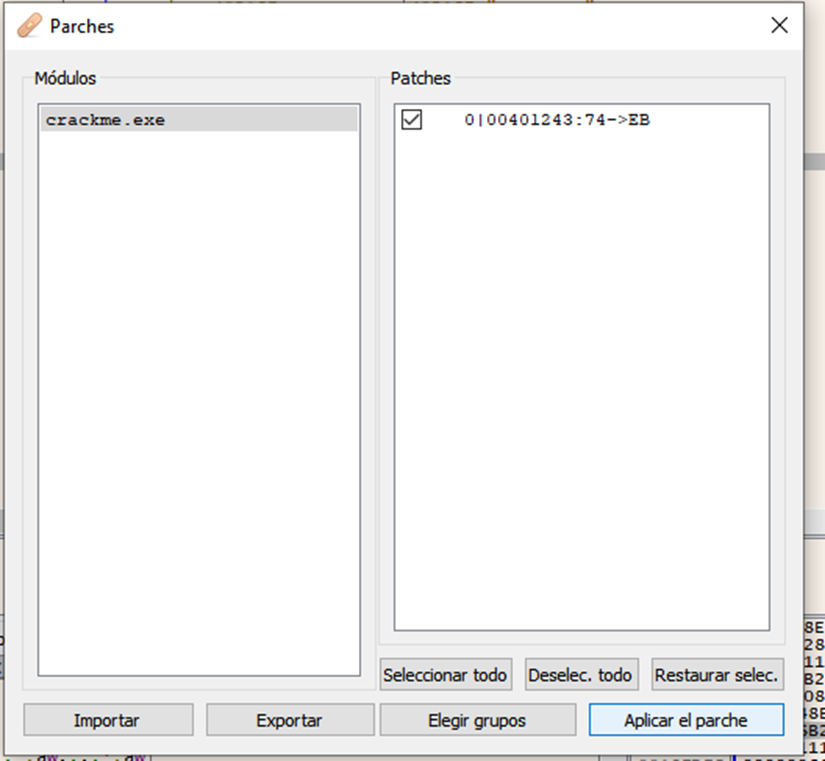
Nos quedará así ahora presionamos aceptar, ahora para que los cambios se guarden presionamos clic derecho->parches
En la ventana que se nos abre le damos a aplicar el parche
Nos abrirá el explorador de archivos
Guardamos la versión modificada con un nombre cualquiera y procedemos a probarla
Abrimos la versión modificada y colocamos un username y serial cualquiera
Y vemos que al presionar ok ¡nos muestra el mensaje de felicitaciones!
Esto concluye nuestro articulo de hoy en el cual en el nos familiarizamos con el depurador y hemos aprendido como depurar un programa e incluso a modificarlo
Hola amigos en esta ocasión estaremos hablando de la ingeniería inversa, aprenderemos que es, resolveremos las dudas más comunes y aprenderemos que es lo necesario para iniciarse en este arte
¿Qué es el reversing?
El reversing o la ingeniería inversa es el proceso de tomar un producto final y obtener información sobre su funcionamiento y\o como fue realizado, existen varios tipos de reversing como, por ejemplo, reversing de hardware, software, mecánico etc. en este artículo nos enfocaremos en la ingeniería inversa de software
¿Para qué se usa el reversing?
El reversing de software se utiliza en muchas áreas diversas, como por ejemplo en análisis de malware, para conocer el funcionamiento y las acciones llevadas a cabo por el mismo con el objetivo de crear las medidas de protección necesarias. También es utilizado en el área de detección de vulnerabilidades, en esta se utiliza la ingeniería inversa para identificar el código con fallas de seguridad y crear exploits que aprovechan esas vulnerabilidades descubiertas. Otros usos que se le pueden dar al reversing son, recuperar código perdido, extender funcionalidades, descifrar algoritmos criptográficos, descifrar protocolos, y también es utilizado en el cracking de software para retirar las medidas de protección del software, y retirar las limitaciones
¿Es el reversing Legal?
El reversing es legal si el producto sometido a ingeniería inversa fue obtenido de manera legal y se es el propietario del mismo, aunque esto puede variar dependiendo de la legislación del país. también es legal realizar ingeniería inversa de malware.
Realizar reversing a determinado software con el objetivo de quitarle las medidas de seguridad y limitaciones para poder usarlo “Full”, es ilegal, a esto se le conoce como cracking
¿Cómo iniciarse en reversing?
Para iniciarse en reversing es muy útil tener una base de programación, aunque esto no debe ser impedimento para empezar, se puede aprender los conceptos de programación conforme se avanza, es necesario conocer las instrucciones más comunes del código ensamblador para la arquitectura objetivo, si se realiza reversing de códigos interpretados es necesario conocer esos lenguajes. Algo muy importante es la práctica, para practicar de manera legal se pueden utilizar crackmes que son programas destinados para aprender técnicas de ingeniería inversa, existen muchos crackmes y de muchos niveles desde principiante hasta algunos muy avanzados.
También existen cursos y comunidades como Crackslatinos que es una gran comunidad donde siempre están dispuestos a darte una mano
¿Cuáles son las herramientas?
A la hora de realizar reversing nos podemos ayudar de muchas herramientas que nos asistirán en el proceso de ingeniería inversa, entre esas herramientas tenemos Desensambladores, decompiladores, debuggers, editores hexadecimales, y otras herramientas útiles que nos asisten en la labor
Desensambladores
Los desensambladores son programas que se encargan de traducir el código maquina a código ensamblador
Debuggers
Los debuggers o depuradores son programas en los cuales podemos ver paso a paso las instrucciones del programa (muchas veces en ensamblador), podemos parar en cualquier punto del programa, editar el flujo de ejecución del programa, editar las instrucciones entre un abanico de posibilidades, sin duda una de las herramientas esenciales a la hora de hacer reversing
Decompiladores
Los decompiladores son herramientas que a partir de un código compilado realizan el proceso de convertir el código maquina a seudocódigo C, este proceso no es perfecto y nunca se recupera el código original sino una aproximación
Editores Hexadecimales
Los editores hexadecimales son programas que nos permiten editar archivos binarios
Detectores de packers
Este tipo de herramientas nos muestran si el programa se encuentra protegido por un packer y que packer información que será de mucha utilidad
Algunas herramientas frecuentemente utilizadas
En este apartado veremos una lista de herramientas frecuentemente utilizadas y su objetivo
IDA
The interactive disassembler es una herramienta super completa para realizar tanto análisis estático como dinámico, esta cuenta con desensamblador, decompilador, debugger, sumado a la capacidad de renombrar variables, crear estructuras crear scripts para automatizar procesos y muchas otras cosas que nos facilitan el análisis. Esta herramienta cuenta tanto con versión gratuita (IDA freeware), como versión de pago
x64dbg
x64dbg es un debugger que soporta debugging tanto de x64 con x32, esta herramienta soporta también un lenguaje de scripting similar al ensamblador
Process Explorer
Esta herramienta que hace parte de sysinternal suite es una herramienta que nos permite ver los procesos en ejecución e información adicional como los handles, las dlls procesos hijos entre otra información
Process Monitor
Esta herramienta también de sysinternal suite nos permite monitorizar las acciones realizadas por un proceso como por ejemplo esta herramienta registrará si el proceso manipula el registro, si crea o modifica archivos entre otras acciones, esta cuenta con una serie de filtros que nos ayudan a encontrar más fácilmente información especifica
WireShark
Esta herramienta la cual es un packet analyzer nos permite capturar los paquetes enviados y recibidos y nos permite filtrar y ver la información de cada paquete
HxD
HxD es un editor hexadecimal bastante usado este nos permite modificar archivos binarios
CFF explorer
Esta herramienta nos permite ver y editar el contenido de archivos portable ejecutable, que es el formato de archivo de los ejecutables de Microsoft Windows
RegShot
Esta herramienta te permite tomar un snapshot del estado actual del registro y uno después de haber ejecutado el software analizado con el objetivo de ver qué cambios sufrió el registro
Palabras Finales
La ingeniería inversa de software es un área que requiere practica y dedicación para dominarla. Pero una vez aprendidas las bases el proceso es más llevadero
En esta ocasión estaremos viendo diferentes herramientas que nos facilitarán la tarea de realizar reversing a programas en Go
¿Por qué es más complicado realizar reversing a programas en GO?
Son varios los factores que dificultan la tarea a los reversers cuando se trata de realizar reversing a los programas en Go como por ejemplo Los programas en GO están enlazados estáticamente (Statically-Linked) es decir que este tendrá incluidos todas las dependencias necesarias para que este funcione. Esto aumenta el tamaño de los mismos, y si abonado a esto no se tienen los símbolos será aún más complicado entender la relación y funcionamiento de las diferentes funciones y podríamos estar analizando código irrelevante para nuestro análisis (código interno de Go). Cuando realizamos reversing a archivos Go sin símbolos no tenemos información tal como los nombres de las variables y funciones con lo que nos dificulta la tarea de entender el propósito de las diferentes funciones y variables además de perdernos fácilmente en las funciones agregadas por Go.
Otra cosa particular de los programas en Go es que las strings no están null terminated en lugar están colocadas pegadas unas con las otras y cuando una función requiere una string se le pasa el puntero y el tamaño de la misma.
En Go Seguir los argumentos y los valores de retorno es más difícil que en programas por ejemplo de c o c++
Realizando pruebas en Go
En esta parte procederemos a compilar un programa en Go y nos dispondremos a analizar el desensamblado con el objetivo de resaltar las diferencias de los programas en Go con otros lenguajes e ilustrar las dificultades que podemos tener a la hora de analizar los mismos
El código que estaremos analizando es el siguiente
package main
import "fmt"
func main() {
var a int
var b int
var res int
fmt.Println("Ingrese el primer numero : ")
fmt.Scan(&a)
fmt.Println("Ingrese el segundo numero : ")
fmt.Scan(&b)
res = suma(a, b)
fmt.Println("La suma es : ", res)
}
func suma(a, b int) int {
return a + b
}
Como podemos ver es un sencillo programa que pide dos números e imprime el resultado de la suma de los dos números, procedamos a ver el desensamblado del programa compilado con símbolos
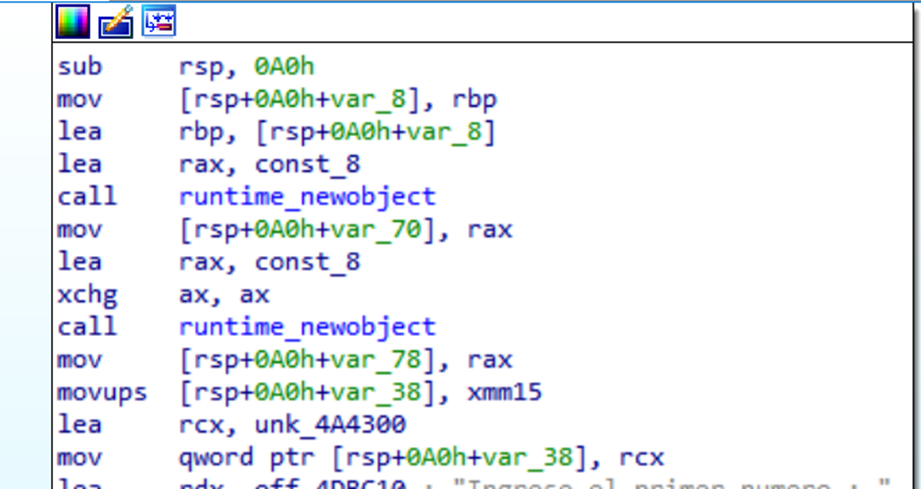
Como vemos en la imagen la función carece del prólogo clásico de las funciones en c o c++ en lugar de eso tiene una comparación y un salto a llamar a runtime_morestack. De esta manera inicializan la mayoría de las funciones en GO en caso de ser necesario allocara más stack en runtime. El código que a nosotros nos concierne es el código escrito por el usuario así que esto lo podemos pasar por alto
Llama a runtime_newobject al parecer para allocar espacio para nuestros dos enteros
Luego llama a fmt_Fprintln pero el paso de argumentos no es tan claro como lo es en otros lenguajes. Coloca en una parte del stack “Ingrese el primer numero”, en ebx tiene os_Stdout en rax tiene File io writer. Pero depurando nos damos cuenta que lo que hace es imprimir “ingrese el primer numero”
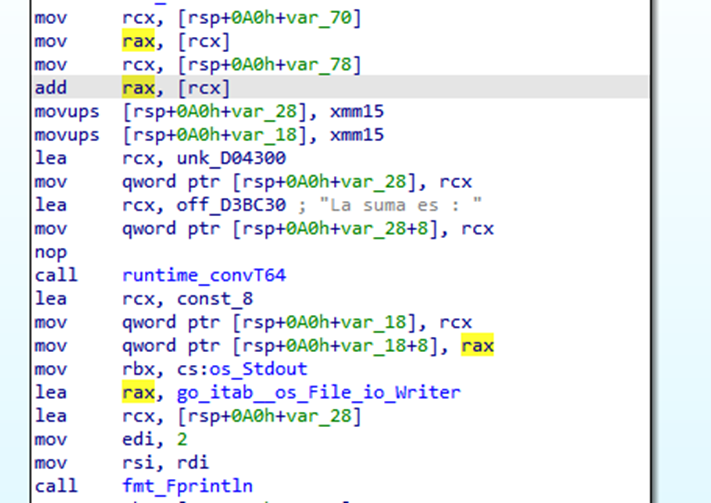
Luego llama a fmt_Fscan en rax tiene file io reader, en rbx tiene os_Stdin y en determinada posición del stack coloca var_70 que es uno de nuestras variables enteras creadas con runtime_newobject y si depuramos nos damos cuenta que escribe en var_70 el numero leído con fmt_Fscan
Imprime ingrese el segundo numero
Lee nuestro segundo numero y lo almacena en var_78
Los suma
Y por último imprime el resultado de la suma
Como nos hemos dado cuenta en este ejemplo es que muchas veces seguir las variables, argumentos y valores de retorno en go puede llegar a ser más complicado que en otros lenguajes, pero podemos ayudarnos de la documentación de go la cual es bastante completa y asistirnos de la depuración
Análisis de programas en Go sin símbolos
En esta parte procederemos a compilar el ejemplo anterior pero esta vez sin símbolos y veremos una herramienta que nos ayudara en el análisis de programas Go cuando estos carecen de símbolos.
Abramos el ejemplo en ida
Como podemos ver en la imagen tenemos 1128 funciones y ninguna tiene nombre o alguna pista si es interna de go o creada por el usuario. Si empezamos a realizar el reversing así va a ser demasiado tedioso.
Gracias a AlphaGolang de sentinel labs esto no tiene que ser así. AlphaGolang es una serie de scripts para idapython que te permiten entre otras cosas recuperar la información de los símbolos, veamos esta serie de scripts en acción
Recrear la tabla pcln
La tabla pcln es una tabla que contiene información sobre las funciones del programa incluyendo los nombres. El primer script lo que hace es recrear dicha tabla
Aquí tenemos los segmentos del programa ejemplo antes de ejecutar el primer script
Ejecutamos el primer script
Y este es el resultado el script crea un segmento que contiene la información de esta tabla
2. Descubrimiento de funciones y renombrado
El siguiente script lo que hace es renombrar las funciones del programa
Estas son las funciones antes de ejecutar el segundo script
Y este es el resultado luego de ejecutar el script. Como vemos ha renombrado la gran mayoría de funciones ahorrándonos un gran trabajo sin embargo no todas fueron renombradas
3. El tercer script organiza las funciones en carpetas, pero por una razón la cual desconozco no funciona en mi maquina
4. El cuarto script arreglas las referencias a las strings
5. El quinto y ultimo script comenta en todas las llamadas a newobject el tipo de objeto
Conclusión
La ingeniería inversa de programas en go puede llegar a tener una mayor dificultad que la ingeniería inversa a otros lenguajes, pero existen Scripts y herramientas que hacen que el proceso de reversing sea mas llevadero
Las aplicaciones Web son siempre una parte vulnerable de los sistemas de información debido a su alto nivel de exposición a en el Internet y a la falta de habilidades de los equipos de desarrollo en prácticas de desarrollo seguro. Por otro lado, durante la pandemia que afectó al mundo en los últimos años, se incrementaron los ciber ataques
Según el reporte anual de Blackberry del 2021, durante la pandemia hubo un aumento del 63% de ciberataques en todo el mundo durante el 2020. De ahí la necesidad de realizar un pentesting a las plataformas Web periódicamente.
Pero ¿Qué es una prueba de penetración Web o pentesting Web?
Un pentesting Web permite evaluar la robustez de los controles de seguridad usados dentro de toda la plataforma Web, como son: servidores, aplicaciones, servicios web y API.
¿Qué se hace durante la prueba de penetración Web?
Durante la prueba de penetración Web, los activos y sistemas de la empresa son inventariados, estudiados y sometidos a escaneo de cualquier vulnerabilidad, y una vez que se han identificado estas, son evaluadas con el fin de identificar si dichas vulnerabilidades son reales y cuál es el riesgo de explotación de las mismas.
El alcance de una auditoria de seguridad web se podrá definir de acuerdo con los siguientes parámetros, los cuales son determinados por la empresa que contrata el servicio de pentesting:
¿Qué se debe y que no se debe incluir en el pentest?
¿Cuál es el nivel de detalle requerido?
¿Cuál es el nivel de ejecución del análisis: Black box (ataque externo sin información provista), Gray o White box (ataque con información provista)?
Y luego de recopilar la información… ¿Cómo la empresa sabe qué debe hacer?
El resultado de esta evaluación es un reporte que permite evaluar la postura de seguridad de su plataforma Web, así como aconsejar al cliente la manera en la que se puede corregir las falencias de seguridad identificadas.
¿Por qué es necesario el Pentesting de Aplicaciones Web?
Internet es un aspecto esencial de muchas tareas del día a día. Millones de personas usan sitios web y aplicaciones para comprar, realizar operaciones bancarias y navegar de forma segura. A medida que las aplicaciones web se vuelven cada vez más populares, se encuentran bajo la amenaza constante de piratas informáticos, virus y terceros malintencionados.
Como muchas aplicaciones web almacenan o envían datos confidenciales, las aplicaciones deben estar seguras en todo momento, especialmente las que usa el público.
El pentesting de aplicaciones web funciona como una medida de control preventivo, lo que le permite analizar cada aspecto de la seguridad de su aplicación web.
Los expertos siguen una lista de verificación de mejores prácticas de pentesting de aplicaciones web , con objetivos generales de:
Probar la eficacia de las políticas de seguridad existentes
Identificar vulnerabilidades desconocidas
Determinar las áreas más vulnerables para un ataque
Pruebe todos los componentes de la aplicación expuestos públicamente (enrutadores, firewalls y DNS)
Encuentre lagunas que puedan estar expuestas al robo de datos
Tipos de Pentesting Web
Hay dos tipos de pentesting web: interno y externo.
Pentesting Interno
Esta es una forma de pentesting manual de aplicaciones web que se realiza utilizando una LAN desde dentro de una organización. Durante este proceso, las aplicaciones web alojadas en la intranet se someten a pruebas. Las pruebas de penetración internas ayudan a identificar las vulnerabilidades que existen dentro de un firewall corporativo.
Los ataques potenciales que pueden ocurrir incluyen:
Ataques a los privilegios de los usuarios
Ataques de phishing
Ataques de ingeniería social
Ataques maliciosos de empleados, contratistas u otras partes descontentos que desean dañar el negocio y tienen acceso a contraseñas y detalles de seguridad.
El pentesting interno intenta acceder a la LAN sin credenciales válidas y descubrir las posibles rutas de ataque malicioso.
Pentesting Externo
Pentesting web externo busca ataques que se originan fuera de una organización. Durante este proceso, a los hackers éticos se les da la dirección IP del sistema de destino y se les pide que simulen ataques externos. Esta es la única información que se les proporciona, ya que utilizan datos públicos para infiltrarse y comprometer el host de destino. El pentesting externo prueba minuciosamente los servidores, firewalls e IDS de una organización.